Kafka介绍
什么是kafka?
什么是Kafka?官网描述是这样子的:
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
Kafka是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统/MQ系统,或者说消息中间件。它最初由Linkedin公司开发,常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
Kafka主要设计目标如下:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- Scale out:支持在线水平扩展

目前kafka可以做更多的事情,而不仅仅是一个传输消息的MQ。
Kafka的名词介绍
broker:Kafka 集群包含一个或多个服务器,服务器节点称为brokerTopic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为TopicPartition:topic中的数据分割为一个或多个partition。每个topic至少有一个partitionproducer:生产者即数据的发布者,该角色将消息发布到Kafka的topic中consumer:消费者可以从broker中读取数据。消费者可以消费多个topic中的数据consumeri gruop:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)Leader:每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partitionFolloewer:Follower跟随Leader,从Leader中拉取消息
Kafka架构
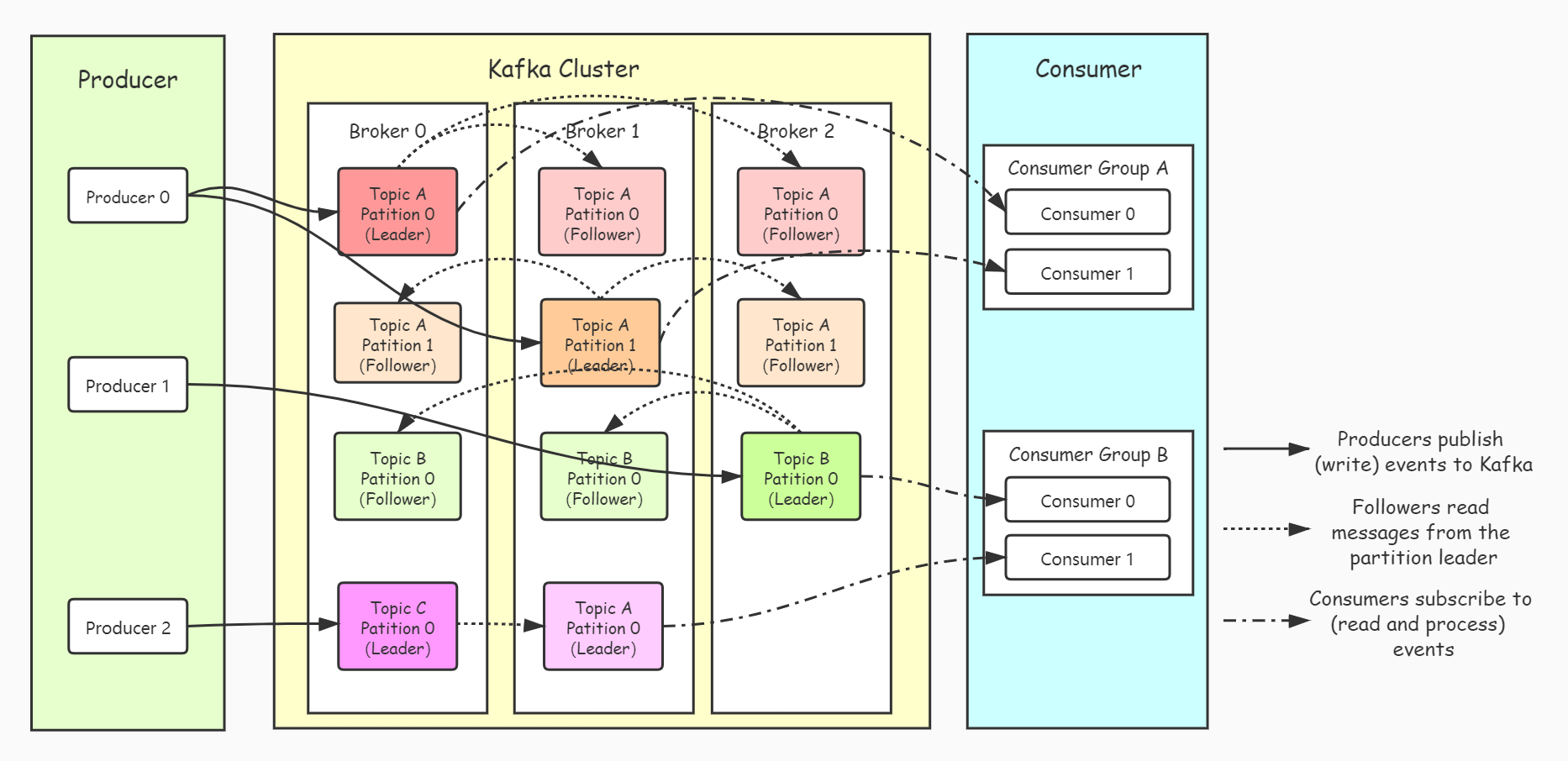
Topic是发布的消息的类别名,一个topic可以有零个,一个或多个消费者订阅该主题的消息。
对于每个topic,Kafka集群都会维护一个分区log,其表现形式就是一个文件夹,如下图所示。
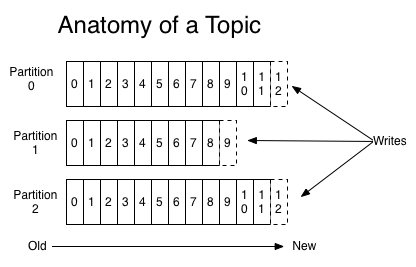
每一个分区都是一个顺序的、不可变的消息队列, 并且可以持续的添加。分区中的消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的。
Kafka集群保持所有的消息,直到它们过期(无论消息是否被消费)。实际上消费者所持有的仅有的元数据就是这个offset(偏移量),也就是说offset由消费者来控制:正常情况当消费者消费消息的时候,偏移量也线性的的增加。但是实际偏移量由消费者控制,消费者可以将偏移量重置为更早的位置,重新读取消息。可以看到这种设计对消费者来说操作自如,一个消费者的操作不会影响其它消费者对此log的处理。
Kafka中采用分区的设计有几个目的。一是可以处理更多的消息,不受单台服务器的限制。Topic拥有多个分区意味着它可以不受限的处理更多的数据。第二,分区可以作为并行处理的单元。
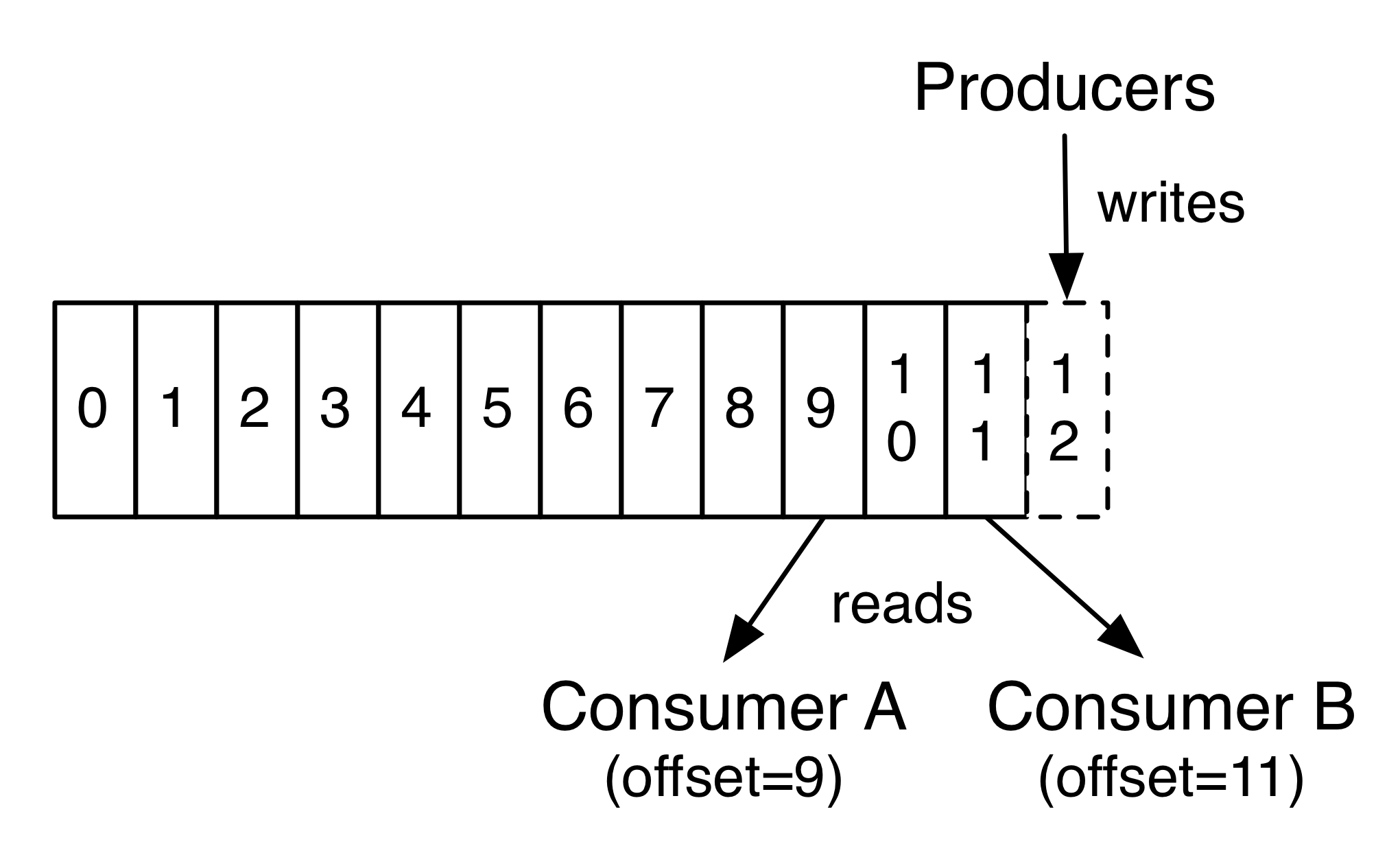
Kafka重要原理
一、Kafka工作流程

如上图所示,Kafka工作流程主要分为6步:
- 生产者从Kafka集群获取分区Leader信息
- 生产者将消息发送给Leader
- Leader将消息写入本地磁盘
- Follower从Leader拉取消息数据
- Follower将消息写入本地磁盘后给Leader发送ACK
- Leader收到所有的Follower的ACK后向生产者发送ACK
二、选择Partition的原则
在Kafka中,如果某个topic有多个partition,producer怎么知道该将数据发往哪个partition呢?
Kafka中有几个原则:
- partition在写入时可以指定需要写入的partition
- 如果没有指定partition,但是设置了数据的key,那么Kafka会根据key的值hash出一个partition
- 如果既没有指定partition,也没有设置key,那么会采用轮询的方式,即每次取一小段时间的数据写入某个partition,下一小段时间再写入下一个partition
三、ACK应答机制
producer在向Kafka写入消息的时候,可以设置参数来确定是否确认Kafka接收到数据,这个参数可以设置为0、1、all。
- 0代表producer往集群发送数据不需要等待集群的返回,不确保消息发送成功。安全性最低但是效率最高。
- 1代表producer往集群发送数据只要leader应答就可以发送下一条,之确保leader接收到消息
- all代表producer往集群发送数据,leader在等到follower回复ACK后,才会向producer回复ACK,producer才会发送下一条消息。安全性最高,但是效率最低。
四、partition结构
partition在服务器上的表现形式就是一个个文件夹,每个partition的文件夹下面会有多组segment文件,每组segment文件有包括.index、.log、.timeindex三个文件,其中.log文件就是实际存储message的地方,而.index和.timeindex是索引文件,用来检索消息。